FPGA Greyscale Decimator
This project was done in partial fulfilment of the NUS MSc CEG Module CEG5203. The assignment page can be found at CEG5203 Assignments
This project was challenging, involving the use of Vivado for preparing the hardware platform, and Vitis for programming the processor. Despite this, it was a great experience of developing a full-stack hardware accelerated platform using the Kria KV260 SOM
Main Topics from CEG5203
-
Full-Stack Hardware Acceleration: Used Vivado for hardware platform preparation and Vitis for software integration. Utilized multiple HLS directives for efficient pipeline computations
-
AXI DMA: Set up DMA for efficient data transfer
-
Algorithmic Optimizations: Line buffer used for efficient memory usage and get around BRAM overflows
Introduction
The project timeline was quite tight. Hence, a relatively simple application was chosen. 1. FPGA receives UART data of a 500x500 RGB Image. 2. FPGA converts the image to greyscale 3. FPGA decimates the image converting it to a 50x50 image and replies with a UART stream of data.
Approach
Multiple optimizations were done to accelerate this as much as possible.
UART
A 500x500 RGB image is consists of \(500\times500\times3=750KB\). However, if you sent as a csv file, each byte is represented as an ASCII string which is then separated by commas. The total size is around \(3000KB\) which takes \(208s\) to transmit via UART.
The solution to this is to send the image as packed bytes via a binary file rather than as a CSV. This conversion was done using OpenCV via a simple python script leading to a ~4x speed up
Memory
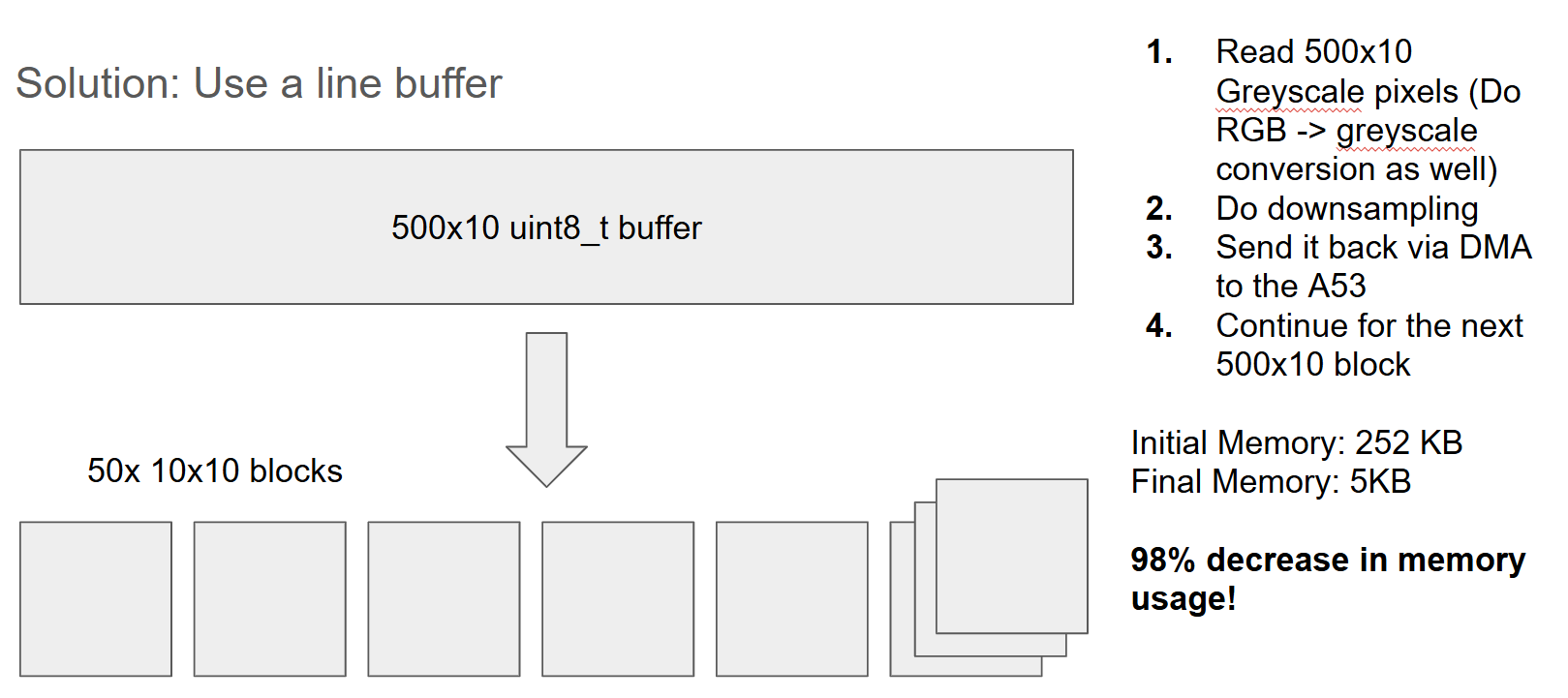
Via a naive processing method, a 250KB buffer is needed to store the incoming buffer. The BRAM required will exceed the KV260's upper limit when trying to build the hardware platform via Vivaodo.
To optimize memory usage, a line buffer was used, using a 500x10 buffer instead of a 500x500 buffer.
HLS Directives
On Vitis, some directives can be used to force the compiler to optimize processing.
RGB to greyscale conversion can be pipelined - #HLS PIPELINE II=1 as each calculation is not dependent on the previous one
int rgb_to_grey_val(int val) {
#pragma HLS PIPELINE II=1
int r = (val >> 16) & 0xFF;
int g = (val >> 8) & 0xFF;
int b = val & 0xFF;
return (r * rWeight + g * gWeight + b * bWeight)>>8;
}
Decimation of each of the \(50\) \(10\times10\) blocks can also be optimized via loop unrolling. To do this, the HLS UNROLL and HLS ARRAY_PARTITION directive was used. Specifically, the unroll factor was set to 5 and the partitioning done was cyclic by a factor of 5 to allow different banks to be read simultaneously.
AXI DMA
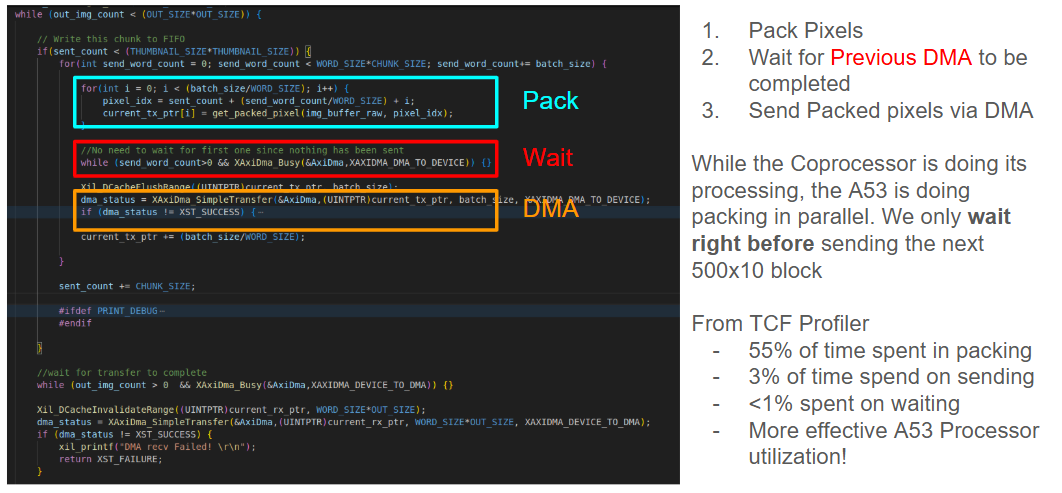
AXI DMA (Direct-Memory-Access) was also utilized to optimize memory access of the buffer. In order to make full use of the hardware accelerator, we want both the A53 and hardware processor to be working at the same time. This means that the processor should not spend alot of time waiting for DMA to be complete.
To do so, I programmed the A53 to do packing while the hardware accelerator was doing the decimation. This meant a careful recording of logic.
Conclusion

This was a pretty challenging project. I wish I had more time to optimize the code, or work on a more challenging problem, but we were given less than 2 weeks to do the project. Nonetheless, I'm proud I was able to implement multiple optimizations and submit a complete project. Using Vivado + Vitis is not something I've done at work or in my personal projects so I'm glad I got the chance to do so!
To further the project, I would have loved to look into other image compression techniques rather than straightforward decimation via averaging.